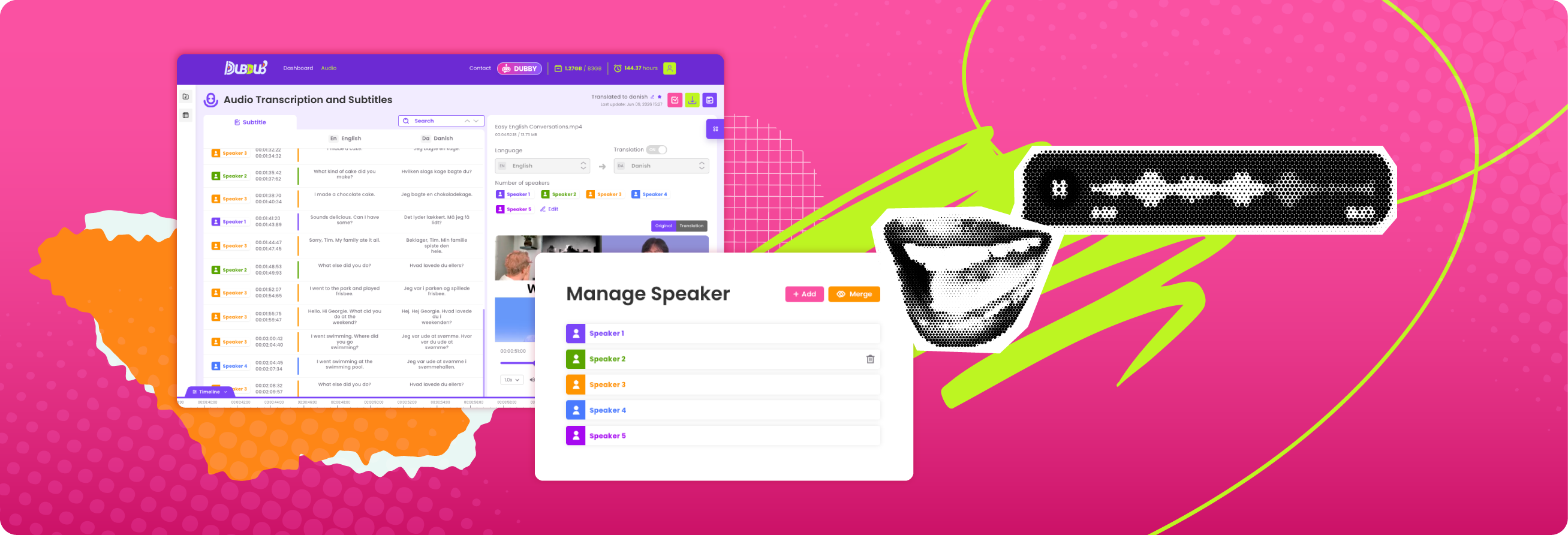
A transcript that says Speaker 1, Speaker 2, Speaker 3 is better than a wall of text. But when you need to know who actually said what, basic separation is not enough. That is where speaker identification in transcription matters - it turns audio into something you can review, publish, quote, and act on without guessing.
For creators, that means cleaner interview transcripts and faster edits. For legal teams, journalists, and researchers, it means accountability. For anyone handling sensitive recordings, it also means one more reason accuracy and privacy cannot be treated as optional.
What speaker identification in transcription actually does
Speaker identification in transcription assigns spoken segments to distinct voices in an audio or video file. In simple cases, the system labels the conversation by speaker so you can tell when one person stops and another starts. In more advanced cases, it can map those segments to known names, such as Host, Client, Attorney, or Interviewee.
That distinction matters. Speaker separation alone tells you there are multiple voices. True identification tries to determine which voice belongs to which person. Some workflows only need separation. Others fall apart without named speakers.
If you are editing a podcast, separating speakers may be enough at first pass. If you are preparing a board meeting record, deposition summary, documentary transcript, or multilingual subtitle file, named attribution saves real time and avoids real mistakes.
Why it matters more than most teams expect
The biggest cost in transcription is rarely the first draft. It is the cleanup. Teams lose time fixing speaker turns, renaming participants, checking quotes, and resolving confusion that should never have made it into the transcript.
When speaker identification works well, the transcript becomes usable much earlier in the workflow. Editors can scan dialogue quickly. Marketing teams can pull accurate quotes. Researchers can track responses by participant. Legal and compliance teams can review statements with more confidence.
It also improves collaboration. A transcript with clear attribution is easier to hand off across departments because context stays attached to the words. Without that, someone always has to go back to the source file and listen again.
For multilingual work, the value compounds. If a transcript feeds subtitles, captions, translations, or repurposed content, speaker confusion spreads downstream. One labeling mistake at the transcript stage can become ten corrections later.
Where speaker identification helps most
Some recordings benefit more than others. Interviews, podcasts, webinars, focus groups, meetings, and panel discussions are obvious examples because multiple people are speaking with changing pace and overlap.
But the strongest use cases are often the ones with accountability attached. Legal proceedings, internal investigations, medical discussions, client calls, and research interviews all depend on knowing who said what. In those contexts, attribution is not a cosmetic feature. It is part of the record.
There is also a practical benefit for teams producing content at scale. If you are processing hours of video every week, manual speaker labeling becomes a hidden tax. Automation does not eliminate review, but it cuts repetitive work dramatically.
What affects accuracy
No vendor should pretend speaker identification is perfect on every file. It depends on the recording.
Clean audio with distinct voices, minimal overlap, and consistent mic quality gives the best results. A one-on-one interview recorded on separate mics is much easier than a crowded Zoom call with crosstalk, laptop fans, and uneven internet audio.
Accents, similar vocal tones, background noise, and interruptions all make identification harder. So does poor channel mixing. If six people speak into one room mic from different distances, the system has less to work with.
This is why real-world expectations matter. A strong tool should perform well on normal business and content workflows, but edge cases still need human review. The goal is not fantasy-level automation. The goal is to remove most of the manual burden without adding complexity.
Speaker separation vs. named speaker recognition
These two features are often lumped together, but they solve different problems.
Speaker separation, sometimes called diarization, breaks the transcript into voice segments. You get clear turn-taking and a readable structure. This alone can save a lot of editing time.
Named speaker recognition goes further. It attempts to match those segments to specific individuals. That can happen through prior voice reference, participant metadata, or manual assignment during review.
For many teams, the best workflow combines both. Let the system separate speakers automatically, then make naming fast and simple in the editor. That strikes the right balance between speed and control.
Why privacy changes the conversation
A lot of transcription tools talk about AI features first and data handling second. That is backwards.
Speaker identification in transcription often involves sensitive source material: client calls, internal meetings, interviews under embargo, legal audio, unreleased media, patient discussions, or proprietary research. If your vendor treats uploads as training fuel, convenience comes with a serious cost.
Privacy-first processing is not a branding extra. It is operationally important. Teams need to know their content is being processed for their benefit, not absorbed into someone else’s model pipeline.
That is especially true when transcripts include speaker labels. Attribution makes the material more identifiable, not less. The better the transcript, the more careful the handling should be.
That is why simple, usage-based transcription platforms with clear pricing and a no-data-training position are gaining ground. They remove two common points of friction at once: uncertainty around cost and uncertainty around ownership.
What to look for in a transcription platform
Start with output quality. If speaker labels are inconsistent, hard to edit, or lost on export, the feature is not doing its job.
Then look at workflow fit. Can you generate a transcript, review speaker labels, export subtitles, and translate content without jumping across five tools? Every extra step creates delay and risk.
Pricing matters too. Speaker identification should not feel like a premium trap layered on top of transcription, subtitles, and translation. Predictable pricing is more than a budgeting preference. It is what lets teams use the feature when they need it instead of rationing usage.
And then there is privacy. Ask the plain question: Is uploaded content used to train models? If the answer is vague, that is your answer.
A practical platform should also support the formats teams actually need after transcription is done. Transcript files, subtitle exports, multilingual outputs, and easy editing are not edge requirements. They are the job.
The trade-off: automation is faster, review is still necessary
The most useful view of speaker identification is not all-or-nothing. It is assisted accuracy.
Automation gives you a structured draft fast. Human review handles the moments where context matters most - similar voices, interrupted speech, or high-stakes quotes. That combination is usually far more efficient than either extreme.
Manual labeling from scratch is slow and expensive. Blind trust in automation is risky. The middle path wins for most professional teams.
This is also where product design matters. If editing speaker labels is clunky, the time savings disappear. Good software keeps review lightweight. You should be confirming and correcting, not rebuilding the transcript.
A smarter standard for modern transcription
Speaker identification used to feel like an advanced feature. It is not anymore. If your team works with conversations, it should be part of the baseline.
Clear attribution makes transcripts more useful, subtitles more reliable, and downstream content easier to produce. It reduces cleanup, improves trust, and helps teams move faster without losing context. For creators, that means less editing friction. For professional teams, it means better records. For privacy-conscious organizations, it means choosing tools that respect the fact that voice data is still your data.
Dub-Dub is built for that standard: fast transcription, speaker-aware workflows, multilingual output, simple pricing, and a hard line on content privacy.
The best transcript is not just accurate text. It is a record you can actually use the moment it lands.



